Threat Hunting Using Newly Registered Domain Lists – Part 1
Author’s Note: This article was inspired by a blog posting over at the SANS Storm Center Infosec Forums. The article, Tracking Newly Registered Domains by Xavier Mertens details ways to use a bash script to download newly registered domain lists and create a Splunk lookup table that can be used to search for domains of interest. The script featured in Mertens’ article appears to be out of date and does not function. I have taken some time to update the script and make it available below. I have updated this script because I wanted to learn more about bash scripting. I am a beginner when it comes to bash scripting and many of my scripts are cobbled together using my Google-foo research. Please be gentle. I make an effort to comment the script below, but it may not be 100% accurate. The script appears to work as of 20190310.
Over the past several days, I have been doing some research into how I can go about implementing another threat hunting query in Splunk. My main concerns as of late have been:
- Brand Protection: I want to know when someone registers a domain name with certain words as part of the domain. Someone may be trying to setup a phishing campaign using an established brand.
- Finding evil domains: Malicious actors typically register a fresh domain for their miscreant deeds. New domains typically do not appear on a blacklist immediately. However, organizations can actively blocking newly registered domains or poor reputation domains to help reduce risk.
- Discover if any devices in an organization have contacted a newly registered domain. This could be a sign of compromise, but is not a silver bullet. It is just another data point.
Newly Registered Domains
There are companies, such as Whois Domain Search (whoisds)
that make newly registered domain lists available for free or on a subscription based model. The SANS article makes mention of a few other services, but ultimately selects the lists provided by Whois Domain Search. This is the site I will use for newly registered domains and in the bash script discussed here.
The Old Script
The script mentioned in the SANS article no longer works. There are several reasons for this:
- The download link format has since been changed by whoisds
- The wget command syntax appears to have changed or was incorrect in the article at the time.
Whoisds appears to have updated the URL from which you can download the newly registered list from. I suspect this was to keep someone from predicting the URL and just downloading the file as illustrated by the below snippet of code from the old script:
#!/bin/bash TODAY=`date --date="-2 day" +"%Y-%m-%d”` DESTDIR=“/home/domains" URL="https://whoisds.com/whois-database/newly-registered-domains/$TODAY.zip/nrd"
The fourth line in the code above grabs a zip file from the whoisds site in the format of yyyy-mm-dd.zip (example, today would be 2019-03-10.zip). This is define by the TODAY variable set on line two. (Please see the SANS blog for a description as to why “-2 day” is included).
When I issued a wget command for this URL, I never received a page in return. So, I went to the whoisds newly registered domain page to see if I could figure out what was going on. After checking a few of the links that I was after in the free downloads section of the page, I quickly discovered what was going on.
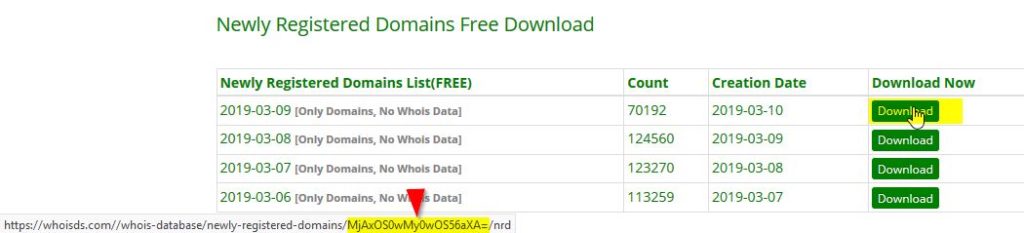
Rather than using the date format for the file name, it now appeared to be a random character string, or did it? As I moved my mouse cursor over each download link, I saw only a few characters change in the link identified by the arrow above. What was this? Well, I have seen enough base64 encoding in my lifetime, so I immediately began to suspect that. I dropped to an Ubuntu shell and entered the below command to see if I could decode it.
user@ubuntu:~$ echo MjAxOS0wMy0wOS56aXA=|base64 -d 2019-03-09.zip
Bingo. Line two above shows it is base64 encoded text. Ok, great, I just need to tweak the script to encode the date in base64. Let’s reverse that and see if we get the same encoded text in the link just to validate our findings:
user@ubuntu:~$ echo 2019-03-09.zip|base64 MjAxOS0wMy0wOS56aXAK
Hmmm. Something doesn’t seem right here. Line two of the output above does not match the encoded text on line one of the Base64 Decode text. Why? Don’t know. I tried this with several other links and I am not sure what is going on here. I also began to think that the base64 command in Ubuntu was incorrect or adding erroneous data. So, I tried another command:
user@ubuntu:~$ echo 2019-03-09.zip|openssl base64 MjAxOS0wMy0wOS56aXAK
Same output. After spending a bit of time on this, I still do not quite understand what was going on. I do know that the letter “K” always appeared at the end of the base64 encoding. So, we can trim that off using a command. This is done on line 19 of the working script below.
Working Script
#!/bin/bash -
#title :newdomains.sh
#description :This script download newly registered domains from whoisds.com.
#author :George J. Silowash
#date :20190310
#version :0.1
#usage :bash newdomains.sh
#notes :Based on a script by Xavier Mertens found here: https://isc.sans.edu/forums/diary/Tracking+Newly+Registered+Domains/23127/
# Get today's date and subtract 1 days. This is due to delays in file release. Set the format of the date to be YYYY-MM-DD
TODAY=`date --date="-1 day" +"%Y-%m-%d"`
#Create a variable to store YYYYMMDD format. This will be used later to archive files.
DIRARCHIVE=`date --date="-1 day" +"%Y%m%d"`
#Add the zip extension to the date to get our complete filename
FILENAME="$TODAY".zip
#Base64 encode the filename so we can place in the URL below.
FNENCODE=`echo $FILENAME | base64`
#Trim the last character in the encoded filename. Not sure why this needs to be done, but URLs are invalid without it.
FNENCODE=${FNENCODE::-1}
#Set your working directories below. These need to exist and you must have permissions to the directories.
#DESTDIR will be created if it does not exist. Here we are archiving the newly created domain files into
#the YYYYMMDD naming format.
DESTDIR="/opt/newdomains/$DIRARCHIVE"
TEMPFILE='/tmp/wget_XXXXXX.zip'
LOGFILE='/tmp/wget_XXXXXX.log'
#If you are running this script on a Splunk host, uncomment the below line and comment the other occurrence of CSVFILE out.
#This will create a lookup table and place it into the appropriate Splunk directory.
#CSVFILE="/opt/splunk/etc/apps/search/lookups/newdomains.csv"
CSVFILE="/opt/newdomains/newdomains.csv"
#Define the URL to use with wget
URL="https://whoisds.com//whois-database/newly-registered-domains/$FNENCODE=/nrd"
#Set the wget user agent
USERAGENT="XmeBot/1.0 (https://blog.rootshell.be/bot/)"
# Check if the destination directory exists
[ -d "$DESTDIR" ] || mkdir -p "$DESTDIR"
# Ensure that the file does not exist already
[ -r "$DESTDIR/$TODAY.txt" ] && rm "$DESTDIR/$TODAY.txt"
wget -o $LOGFILE -O $TEMPFILE --user-agent="$USERAGENT" $URL
RC=$?
if [ "$RC" != "0" ]; then
echo "[ERROR] Cannot fetch $URL"
cat $LOGFILE
else
unzip -d $DESTDIR $TEMPFILE >$LOGFILE 2>&1
RC=$?
if [ "$RC" != "0" ]; then
echo "[ERROR] Cannot unzip $TEMPFILE"
cat $LOGFILE
else
echo "newdomain" >$CSVFILE
cat "$DESTDIR/domain-names.txt" >>$CSVFILE
rm $LOGFILE $TEMPFILE
fi
#rm $DESTDIR/domain-names.txt
fi
Features
The old script deleted your work files once done with them. I thought it would be interesting to archive these files should you want to search them for a particular domain. This was done by adding the DIRARCHIVE variable on line 13. Each time the script runs, the data will be stored a directory with the naming convention YYYYMMDD.
Limitations
If whoisds changes the URL format, this script will crash and burn. It also appears to be limited to the “.com” Top Level Domain (TLD). This is only a small chunk of TLDs out there. I will be looking to expand on these.
Future Work
I intend on expanding on this post. I have some ideas for future threat hunting activities, including Splunk queries, brand protection, and domain research. In a future posting, I will cover a Splunk query that could be helpful in detecting evil using this script. Please see the SANS article for a preview of that as the query will be based off the one in that article.
